









PyTorch是一个开源的机器学习和深度学习库,主要由Facebook开发,用于越来越广泛的使用案例,以实现机器学习任务的自动化,如图像识别、自然语言处理、翻译、推荐系统等。PyTorch主要用于研究,近年来,由于其易于使用和部署,它在业界也获得了巨大的吸引力。
谷歌云人工智能平台是一个完全管理的端到端平台,用于谷歌云上的数据科学和机器学习。利用谷歌在人工智能方面的专业知识,AI平台提供了一个灵活、可扩展和可靠的平台来运行你的机器学习工作负载。AI平台通过深度学习容器内置了对PyTorch的支持,这些容器已经过性能优化、兼容性测试,可以随时部署。
在这个新的系列博文《谷歌云上的PyTorch》中,我们旨在分享如何大规模构建、训练和部署PyTorch模型以及如何在谷歌云上创建可重复的机器学习管道。

为什么要在谷歌云AI平台上使用PyTorch?
云AI平台提供了灵活和可扩展的硬件和安全的基础设施,以训练和部署基于PyTorch的深度学习模型。
- 灵活性。AI平台笔记本和AI平台训练提供了灵活性,可以设计你的计算资源以匹配任何工作负载,同时平台管理大部分的依赖关系、网络和监控。将您的时间用于建立模型,而不是担心基础设施。
- 可扩展性。使用预建的PyTorch容器或自定义容器在AI平台笔记本上运行您的实验,并通过在GPU或TPU上训练模型,使用AI平台训练的高可用性来扩展您的代码。
- 安全性。AI平台利用相同的全球规模的技术基础设施,旨在通过谷歌的整个信息处理生命周期提供安全。
- 支持。AI平台与PyTorch和NVIDIA密切合作,确保AI平台和NVIDIA GPU之间的顶级兼容性,包括PyTorch框架支持。
以下是谷歌云上对PyTorch的支持情况的快速参考
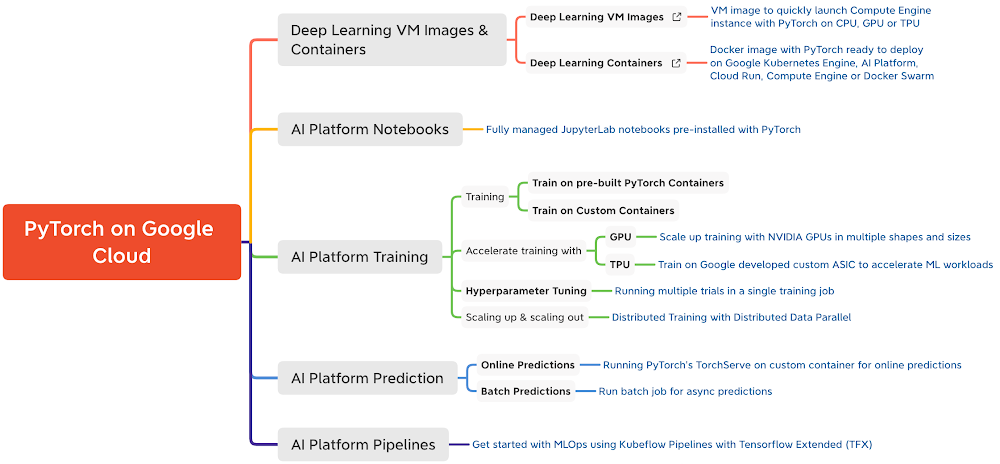
(点击放大)
在这篇文章中,我们将介绍。
你可以在GitHub仓库和Jupyter笔记本上找到本博文的配套代码。
让我们开始吧!
用例和数据集
在这篇文章中,我们将使用PyTorch对Huggingface变形器库中的一个变形器模型(BERT-base)进行微调,以完成情感分析任务。BERT(Bidirectional Encoder Representations from Transformers)是一个变压器模型,它以自我监督的方式在大量未标记文本的语料库中进行了预训练。我们将在AI平台笔记本上开始对IMDB情感分类数据集进行实验。我们建议使用一个计算量有限的AI平台笔记本实例,用于开发和实验目的。一旦我们对笔记本上的本地实验感到满意,我们将展示如何将相同的Jupyter笔记本提交给AI平台训练服务,以便用更大的GPU形状来扩展训练。AI平台训练服务通过为训练工作启动基础设施并在训练完成后将其关闭来优化训练管道,而不需要你去管理基础设施。

在接下来的文章中,我们将展示如何在AI Platform Prediction服务上部署和服务这些PyTorch模型。
在AI平台笔记本上创建一个开发环境
我们将使用JupyterLab笔记本作为AI Platform Notebooks上的开发环境。在你开始之前,你必须在谷歌云平台上设置一个项目,并启用AI Platform Notebooks API。
请注意,当你创建一个AI平台笔记本实例时,你将被收费。您只需为您的笔记本实例启动和运行的时间付费。您可以选择停止实例,这将保存您的工作,只对启动磁盘存储收费,直到您重新启动实例。请在您完成后删除该实例。
你可以创建一个AI平台的笔记本实例。
- 使用AI平台深度学习虚拟机(DLVM)图像中预先构建的PyTorch图像或
- 使用带有您自己的软件包的自定义容器
使用预先构建的PyTorch DLVM镜像创建一个笔记本实例
AI Platform Notebooks实例是AI Platform深度学习虚拟形象实例,启用了JupyterLab笔记本环境并可随时使用。AI平台笔记本提供PyTorch图像系列,支持多个PyTorch版本。你可以从谷歌云控制台或命令行界面(CLI)创建一个新的笔记本实例。我们将使用gcloud CLI来创建NVIDIA Tesla T4 GPU上的笔记本实例。从Cloud Shell或任何安装了Cloud SDK的终端,运行以下命令来创建一个新的笔记本实例。
要与新的笔记本实例进行交互,请进入Google Cloud Console中的AI Platform Notebooks页面,点击新实例旁边的 “OPEN JUPYTERLAB “链接,当它可以使用时,它就会变得活跃。
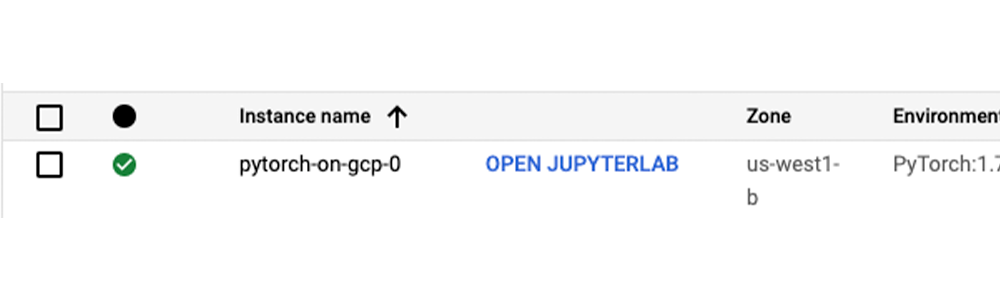
使用PyTorch进行实验所需的大部分库已经通过预先构建的PyTorch DLVM镜像安装在新实例上。要安装额外的依赖项,请在笔记本单元中运行%pip install 。对于情感分类的用例,我们将安装额外的软件包,如Hugging Face变换器和数据集库。
带有自定义容器的笔记本实例
在Notebook实例中用pip安装依赖项的另一种方法是将依赖项打包在源自AI平台深度学习容器图像的Docker容器图像中,并创建一个自定义容器。你可以使用这个自定义容器来创建AI平台笔记本实例或AI平台训练作业。下面是一个使用自定义容器创建笔记本实例的例子。
1.创建一个Dockerfile ,用AI平台深度学习容器图像之一作为基础图像(这里我们使用PyTorch 1.7 GPU图像)并运行/安装你需要的包或框架。对于情感分类的用例,包括转化器和数据集。
2. 从终端或云端壳 使用云端构建从Docker文件构建图像,并获得图像位置gcr.io/{project_id}/{image_name}
3. 使用命令行用步骤2中创建的自定义镜像创建一个笔记本实例。
在AI平台上训练一个PyTorch模型
在创建了AI平台笔记本实例后,你可以开始进行实验了。让我们来看看这个用例的模型具体情况。
模型的具体情况
为了分析IMDB数据集中的电影评论的情感,我们将对Hugging Face的预训练的BERT模型进行微调。微调涉及到将一个已经为某一特定任务训练过的模型,然后为另一个类似的任务调整该模型。具体来说,调整包括复制预训练模型中的所有层,包括权重和参数,除了输出层。然后添加一个新的输出分类器层,预测当前任务的标签。最后一步是从头开始训练输出层,而预训练模型的所有层的参数都被冻结。这允许从预训练的表征中学习,并 “微调 “与具体任务更相关的高阶特征表征,例如在本案例中分析情感。
对于这里分析情感的场景,预训练的BERT模型已经编码了很多关于语言的信息,因为该模型是以自我监督的方式在一个大型的英语数据语料库上训练的。现在,我们只需要使用它们的输出作为情感分类任务的特征对其进行轻微调整。这意味着在一个更小的数据集上进行更快的开发迭代,而不是用一个更大的训练数据集来训练一个特定的自然语言处理(NLP)模型。
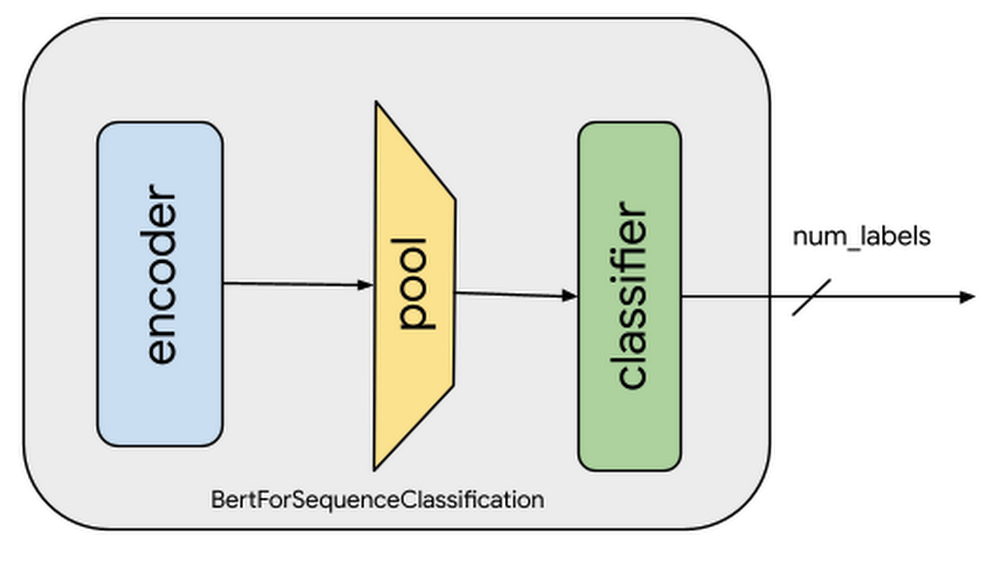
带有分类层的预训练模型。蓝框表示预训练的BERT编码器模块。编码器的输出被汇集到线性层,输出数量与目标标签(类别)的数量相同。
为了训练情感分类模型,我们将。
- 对评论数据进行预处理和转换(标记化)。
- 加载预训练的BERT模型,并为情感分析添加序列分类头
- 为句子分类微调BERT模型
以下是预处理数据和微调预训练BERT模型的代码片段。关于这些任务的完整代码和详细解释,请参考Jupyter笔记本。
在上面的片段中,注意到编码器(也被称为基础模型)的权重没有被冻结。这就是为什么选择一个非常小的学习率(2e-5),以避免预训练表征的损失。学习率和其他超参数在TrainingArguments对象下被捕获。在训练过程中,我们只捕获准确度指标。你可以修改compute_metrics函数来捕获和报告其他指标。
我们将在本系列的下一篇文章中探讨与云端AI平台超参数调优服务的整合。
在云端AI平台上训练模型
虽然你可以在你的AI平台笔记本实例上做本地实验,但对于更大的数据集或模型,往往需要垂直扩展的计算资源或水平分布的训练。执行这项任务的最有效方法是AI平台训练服务。AI Platform Training负责创建任务所需的指定计算资源,执行训练任务,并确保训练工作完成后删除计算资源。
在用AI平台训练运行训练应用程序之前,必须将具有所需依赖性的训练应用程序代码打包并上传到你的谷歌云项目可以访问的谷歌云存储桶。有两种方法来打包应用程序并在AI平台训练上运行。
- 使用Python设置工具手动打包应用程序和Python依赖项
- 使用自定义容器,使用Docker容器打包依赖项
你可以用任何你喜欢的方式来结构你的训练代码。请参考GitHub仓库或Jupyter笔记本,了解我们推荐的结构化训练代码的方法。
使用Python包装来手动构建
对于这个情感分类任务,我们必须将训练代码与标准的Python依赖项–transformers,datasets 和tqdm –打包在setup.py 文件中。setup.py 内的find_packages() 函数将训练代码作为依赖项包含在软件包中。
现在,你可以在安装了gcloud SDK的情况下,从Cloud Shell或终端使用gcloud命令向云端AI平台训练提交训练作业。gcloud ai-platform jobs提交训练命令在GCS bucket上对训练应用程序进行阶段性训练,并提交训练作业。我们将2个NVIDIA Tesla T4 GPU附加到训练作业中,以加速训练。
使用自定义容器进行训练
要创建一个带有自定义容器的训练作业,你必须定义一个Docker文件来安装训练作业所需的依赖项。然后,你在本地构建并测试你的Docker镜像,以验证它,然后再将其用于AI平台培训。
在提交训练作业之前,你需要将图像推送到谷歌云容器注册中心,然后使用gcloud ai-platform jobs submittraining命令将训练作业提交到云AI平台训练。
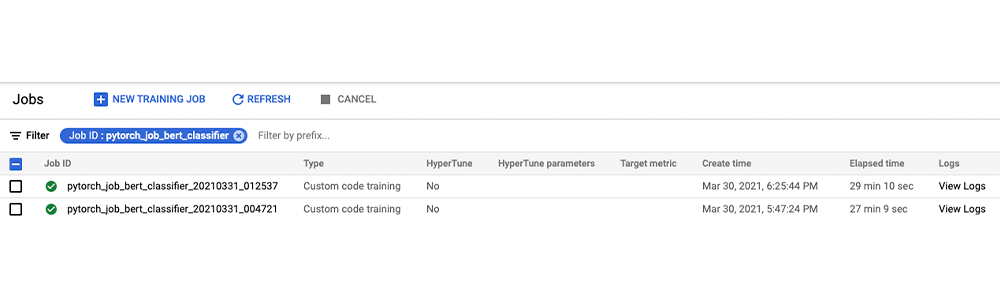
一旦提交了作业,你可以在谷歌云控制台或使用gcloud命令监控训练作业的状态和进度,如下图所示。
你也可以从谷歌AI平台作业控制台监控作业状态并查看作业日志。
让我们用几个例子在本地对训练好的模型运行预测调用(完整代码请参考笔记本)。本系列的下一篇文章将告诉你如何在AI平台预测服务上部署这个模型。
清理笔记本环境
在你完成实验后,你可以停止或删除AI笔记本实例。删除AI笔记本实例以防止进一步收费。如果你想保存你的工作,你可以选择停止该实例,而不是。
下一步是什么?
在这篇文章中,我们探索了云端AI平台笔记本作为PyTorch模型开发的完全可定制的IDE。然后,我们在云端AI平台训练服务上训练了模型,这是一个完全可管理的服务,用于大规模训练机器学习模型。
参考文献
库
- 的代码和附带的笔记本
在本系列的下一篇文章中,我们将研究云端AI平台上的超参数调优和在AI平台预测服务上部署PyTorch模型。我们鼓励你探索我们所研究的云端AI平台的功能。
请继续关注。谢谢您的阅读!有问题或想聊天?在这里找到作者–Rajesh[Twitter|LinkedIn] 和 Vaibhav[LinkedIn]。
感谢Amy Unruh和Karl Weinmeister的帮助和评论。













![[桜井宁宁]COS和泉纱雾超可爱写真福利集-一一网](https://www.proyy.com/skycj/data/images/2020-12-13/4d3cf227a85d7e79f5d6b4efb6bde3e8.jpg)
![[桜井宁宁] 爆乳奶牛少女cos写真-一一网](https://www.proyy.com/skycj/data/images/2020-12-13/d40483e126fcf567894e89c65eaca655.jpg)
