








Redis 五种基本数据结构
当我们在本文中提到Redis的“数据结构”,可能是在两个不同的层面来讨论它。第一个层面,是从使用者的角度。比如:
- string
- list
- hash
- set
- sorted set
这一层面也是Redis暴露给外部的调用接口,称之为Redis数据类型。第二个层面,是Redis为了实现上述数据结构,引入的内部数据结构。比如:
- dict
- sds
- ziplist
- quicklist
- skiplist
本文从使用者角度的数据结构出发,介绍每个数据结构涉及的内部数据结构。比如string用到了sds结构,list用到了quicklist和ziplist。Redis数据类型和底层数据结构的对应关系如下:

Redis对象
Redis使用对象来表示数据库中的键和值,其中键对象一般为字符串对象,值对象则可以指向不同类型的数据。
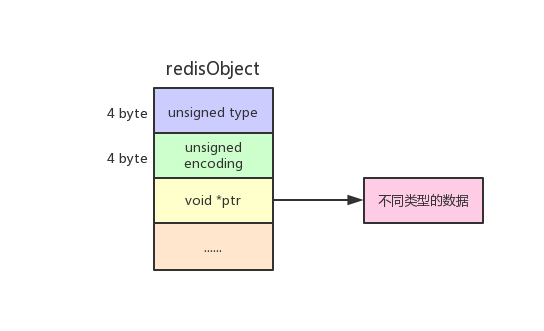
type记录了对象类型,可以取值为REDIS_STRING、REDIS_LIST、REDIS_HASH、REDIS_SET、REDIS_ZSET,分别表示string、list、hash、set、zset对象。
encoding表示对象底层的编码和存储方式,取值和对象的对应关系如下表所示:
| 编码常量 | 底层数据结构 |
|---|---|
| REDIS_ENCODING_INT | long类型的整数 |
| REDIS_ENCODING_EMBSTR | embstr编码的动态字符串(SDS) |
| REDIS_ENCODING_RAW | 简单动态字符串(SDS) |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_QUICKLIST | 快表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳跃表+字典 |
ptr是指向具体内存数据结构的指针,由于Redis有多种数据类型,每种数据类型都有多种数据结构可以实现,因此ptr用void来修饰。
string
当string保存的是一个整数值,并可以用long型存储时,那么string对象会将整数值保存在ptr里面,将void*转换成long型,编码为int;当整数值太大无法用long型存储时,会将整数值转换成字符串,用SDS来存储,编码为embstr或者raw。
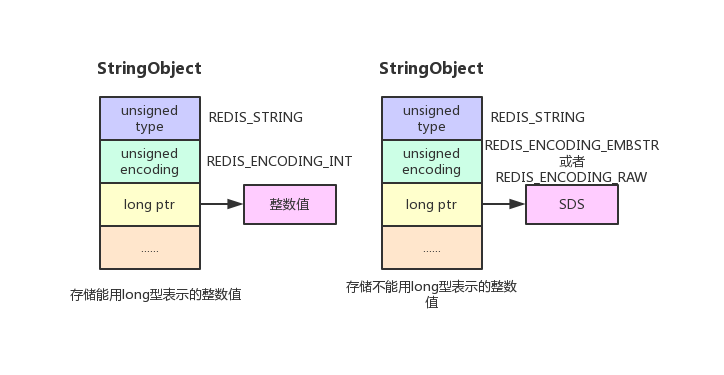
当string对象保存的是一个字符串,并且字符串长度小于等于39字节时,就会用embstr编码来保存字符串值。此时SDS与字符串redisObject紧邻在一起,只需申请一次内存。

当字符串内容长度大于39字节时,会用raw编码来保存字符串,申请内存时需申请两次,一次用来存储redisObject,另一次用于存储SDS结构。释放内存也需要两次释放。

SDS的数据结构
在Redis3.2中,SDS的定义如下:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
复制代码每个字段的含义如下:
- len:记录当前已使用的字节数(不包括’\0’),获取SDS长度的复杂度为O(1)
- alloc:记录当前字节数组总共分配的字节数量(不包括’\0’)
- flags:标记当前字节数组的属性,是sdshdr8还是sdshdr16等
- buf:字节数组,用于保存字符串,包括结尾空白字符’\0′
针对不同的string长度,使用不同类型保存len和alloc,是Redis节省内存的一种优化。
扩容
当字符串长度小于1M时,扩容是新长度的两倍,如果超过1M,扩容时一次只会多扩1M的空间。
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s); /* sds剩余可用 即s.alloc - s.len */
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* 有足够空间则返回 */
if (avail >= addlen) return s;
len = sdslen(s); /* 字符串长度 */
sh = (char*)s-sdsHdrSize(oldtype); /* sdshdr指针 */
newlen = (len+addlen); /* 新长度 */
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen); /* 新长度合适的sds类型 */
/* 扩容时一般不为SDS_TYPE_5 */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type); /* 新sdshdr大小 */
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* 分配内存,拷贝原字符串,释放原sds内存,并设置好flags以及len */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
复制代码缩容&惰性释放空间
释放内存的过程中修改len和free字段,并不释放实际占用内存。例如sdsclear操作:
// 将len字段设置为0,但内存空间不释放。
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '\0';
}
复制代码当然必要的时候也可以调用sdsRemoveFreeSpace,主动缩容。
C字符串与SDS对比
- 结构中存储字符串长度,获取字符长度只需要常量时间复杂度,而原生字符串则需要遍历数组;
- 二进制安全,可以存储字节数据,因为存储字符串长度,不会提前遇到\0字符而终止;
- 杜绝缓冲区溢出,C语言字符串本身不记录数组长度,增加操作时,分配内存不足时容易造成缓冲区溢出,而sds因为存在alloc,会在修改时,检查空间大小是否满足;
- 内存预分配以及惰性删除,减少内存重新分配次数;
- 兼容C标准库中的部分字符串函数。
list
考虑到链表的附加空间相对太高,对于64位操作系统来说,prev 和 next 指针就要占去 16 个字节 ;并且链表的每个节点都单独分配,内存碎片化程度较高,list对象在底层使用quicklist(快速列表)来存储(在redis3.2之后)。quicklist是由一个个ziplist组成的链表,每个ziplist连续地存放多个list元素,ziplist中的每个entry块存放一个list元素。相对链表实现来说,quicklist可以大大节省prev 和 next 指针的占用空间。

ziplist
ziplist的数据结构,
struct ziplist<T>{
int32 zlbytes; //压缩列表占用字节数
int32 zltail_offset; //最后一个元素距离起始位置的偏移量,用于快速定位到最后一个节点
int16 zllength; //元素个数
T[] entries; //元素内容
int8 zlend; //结束位 0xFF
}
复制代码quicklist的pop操作,先从头部或尾部节点的ziplist中把对应的数据项删除,如果在删除后ziplist为空了,那么对应的头部或尾部节点也要删除。
quicklist不仅实现了从头部或尾部插入,也实现了从任意指定的位置插入。quicklistInsertAfter和quicklistInsertBefore就是分别在指定位置后面和前面插入数据项。
- 当插入位置所在的ziplist大小没有超过限制时,直接插入到ziplist中就好了;
- 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小没有超过限制,那么就转而插入到相邻的那个quicklist链表节点的ziplist中;
- 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小也超过限制,这时需要新创建一个quicklist链表节点插入。
- 对于插入位置所在的ziplist大小超过了限制的其它情况(主要对应于在ziplist中间插入数据的情况),则需要把当前ziplist分裂为两个节点,然后再其中一个节点上插入数据。
每一个数据项的构成:
: 表示前一个数据项占用的总字节数。这个字段的用处是为了让ziplist能够从后向前遍历(从后一项的位置,只需向前偏移prevlen个字节,就找到了前一项)。这个字段采用变长编码。它有两种可能,或者是1个字节,或者是5个字节:
- 如果前一个数据项占用字节数小于254,那么就只用一个字节来表示,这个字节的值就是前一个数据项的占用字节数。
- 如果前一个数据项占用字节数大于等于254,那么就用5个字节来表示,其中第1个字节的值是254(作为这种情况的一个标记),而后面4个字节组成一个整型值,来真正存储前一个数据项的占用字节数。(不用255,是因为它已经定义为ziplist结束标记的值了)
: 有9中编码方式
- |00pppppp| – 1 byte。string值。剩余的6个bit用来表示长度值,最高可以表示63 (2^6-1)。
- |01pppppp|qqqqqqqq| – 2 bytes。string值。剩余的14个bit用来表示长度值,最高可以表示16383 (2^14-1)。
- |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| – 5 bytes。第1个字节是10000000,剩余的4个字节来表示长度值。
- |11000000| – 3 byte。字段占用1个字节,值为0xC0,后面的数据存储为2个字节的int16_t类型。
- |11010000| – 5 byte。字段占用1个字节,值为0xD0,后面的数据存储为4个字节的int32_t类型。
- |11100000| – 9 byte。字段占用1个字节,值为0xE0,后面的数据存储为8个字节的int64_t类型。
- |11110000| – 4 byte。字段占用1个字节,值为0xF0,后面的数据存储为3个字节长的整数。
- |11111110| – 2 byte。字段占用1个字节,值为0xFE,后面的数据存储为1个字节的整数。
- |1111xxxx| – – (xxxx的值在0001和1101之间)。这是一种特殊情况,xxxx从1到13一共13个值,这时就用这13个值来表示真正的数据。注意,这里是表示真正的数据,而不是数据长度了。也就是说,在这种情况下,后面不再需要一个单独的字段来表示真正的数据了,而是和合二为一了。
hash
当元素个数较少,并且每个元素较短时,hash对象底层通过ziplist来存储,field和value存储在两个相邻的entry中。

当元素个数较多,或者存在较长的元素时,hash对象会转为dict(字典)存储。临界点的元素个数和元素长度可由参数hash-max-ziplist-entries和hash-max-ziplist-value进行配置,默认值分别为512和64。
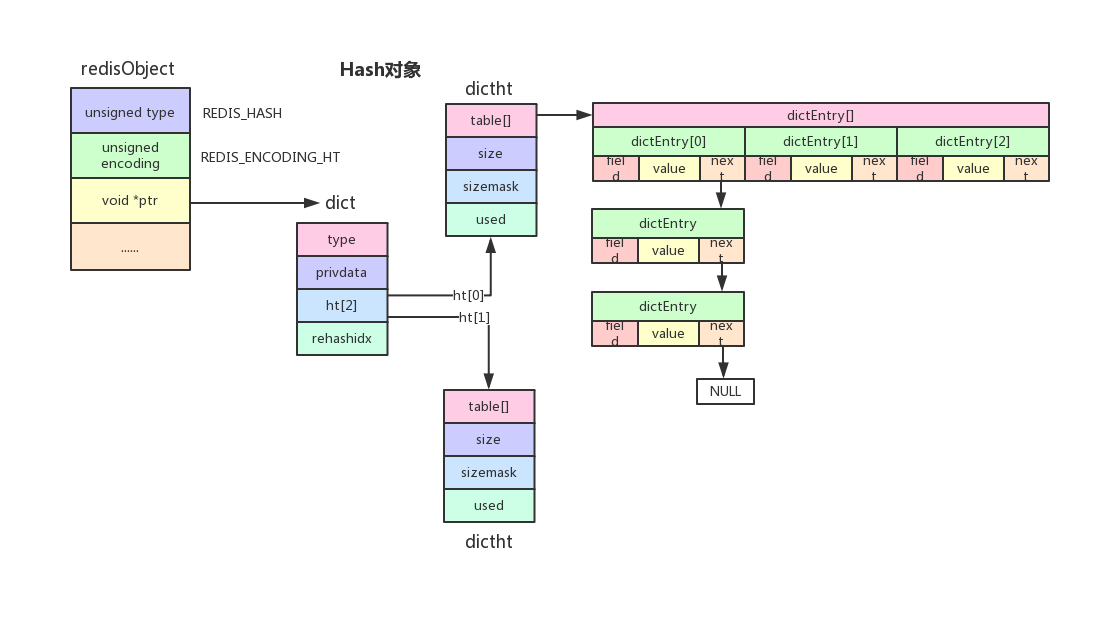
dict
一个dict由如下若干项组成:
- 一个指向dictType结构的指针(type)。它通过自定义的方式使得dict的key和value能够存储任何类型的数据。
- 一个私有数据指针(privdata)。由调用者在创建dict的时候传进来。
- 两个哈希表(ht[2])。只有在重哈希的过程中,ht[0]和ht[1]才都有效。而在平常情况下,只有ht[0]有效,ht[1]里面没有任何数据。
- 当前重哈希索引(rehashidx)。如果rehashidx = -1,表示当前没有在重哈希过程中;否则,表示当前正在进行重哈希,且它的值记录了当前重哈希进行到哪一步了。
dictType结构包含若干函数指针,用于dict的调用者对涉及key和value的各种操作进行自定义。这些操作包含:
- hashFunction,对key进行哈希值计算的哈希算法。
- keyDup和valDup,分别定义key和value的拷贝函数,用于在需要的时候对key和value进行深拷贝,而不仅仅是传递对象指针。
- keyCompare,定义两个key的比较操作,在根据key进行查找时会用到。
- keyDestructor和valDestructor,分别定义对key和value的析构函数。
私有数据指针(privdata)就是在dictType的某些操作被调用时会传回给调用者。
需要详细察看的是dictht结构。它定义一个哈希表的结构,由如下若干项组成:
- 一个dictEntry指针数组(table)。key的哈希值最终映射到这个数组的某个位置上(对应一个bucket)。如果多个key映射到同一个位置,就发生了冲突,那么就拉出一个dictEntry链表。
- size:标识dictEntry指针数组的长度。它总是2的指数。
- sizemask:用于将哈希值映射到table的位置索引。它的值等于(size-1),比如7, 15, 31, 63,等等,也就是用二进制表示的各个bit全1的数字。每个key先经过hashFunction计算得到一个哈希值,然后计算(哈希值 & sizemask)得到在table上的位置。相当于计算取余(哈希值 % size)。
- used:记录dict中现有的数据个数。它与size的比值就是装载因子(load factor)。
dictht的扩容与缩容
Redis中的哈希表通过load_factor(负载因子)来决定是否扩容或者缩容,负载可由公式ht[0].used/ht[0].size算得。
扩容
扩容时需考虑服务器当前是否正在执行bgsave或者bgrewriteaof,若服务器当前正在bgsave或bgrewriteaof,应该尽量避免扩容,此时触发扩容的条件是load_factor为5;否则当load_factor为1时就开始扩容。之所以要这样做,是因为bgsave或bgrewriteaof命令会fork子进程来遍历内存,若内存无变更则与父进程共享内存页,修改内存数据时需将内存页拷贝一份出来进行修改(这就是传说中的写时复制),修改内存数据不但在拷贝内存页时会消耗CPU资源,而且会消耗更多的内存空间。而扩容时需要将旧哈希表元素rehash到新哈希表,从而造成内存数据变更,因此要尽量避免扩容。
为了方便rehash,扩容时数组容量会扩展到(第一个大于2倍哈希表元素个数)的2^n。
缩容
缩容则不需要考虑bgsave或者bgrewriteaof,当负载因子为0.1时会触发缩容。缩容时也需要进行rehash操作,数组长度会缩减为(第一个大于哈希表元素个数)的2^n,新下标也可通过公式hash(key) & sizemask算出来。
渐进式rehash
上面说到,哈希表在扩容和缩容时都需要rehash,由于Redis是单线程处理的,如果字典中的元素太多,一次性执行rehash操作会造成卡顿,因此Redis采用渐进式rehash的策略,在查找、插入、删除操作时,对其进行迁移。如果一直没有被访问,Redis会在定时任务中对其执行rehash。
渐进式rehash每次将重哈希至少向前推进n步(除非不到n步整个重哈希就结束了),每一步都将ht[0]上某一个bucket(即一个dictEntry链表)上的每一个dictEntry移动到ht[1]上,它在ht[1]上的新位置根据ht[1]的sizemask进行重新计算。rehashidx记录了当前尚未迁移(有待迁移)的ht[0]的bucket位置。
如果重hash被调用的时候,rehashidx指向的bucket里一个dictEntry也没有,那么它就没有可迁移的数据。这时它尝试在ht[0].table数组中不断向后遍历,直到找到下一个存有数据的bucket位置。如果一直找不到,则最多走n*10步,本次重哈希暂告结束。
最后,如果ht[0]上的数据都迁移到ht[1]上了(即d->ht[0].used == 0),那么整个重哈希结束,ht[0]变成ht[1]的内容,而ht[1]重置为空。
set
当集合元素全为能用long声明的整数值,并且元素个素不大于512个(可通过参数set-max-intset-entries配置)时,集合数据通过intset来存储,intset中的元素按从小到大的顺序排列。其他情况下,集合数据一律使用dict(字典)来存储,字典的键为集合元素的value,字典的值为null。

zset
默认情况下,当zset中的元素个数不大于128(通过参数zset-max-ziplist-entries控制),并且所有元素的长度都不大于64字节(通过参数zset-max-ziplist-value控制)时,zset底层采用ziplist来存储,相邻的两个entry分别表示value和score。如果两个条件有一个不满足,都采用hashtable+skiplist的形式存储,其中hashtable存储value和score的映射关系,skiplist按顺序存储value。
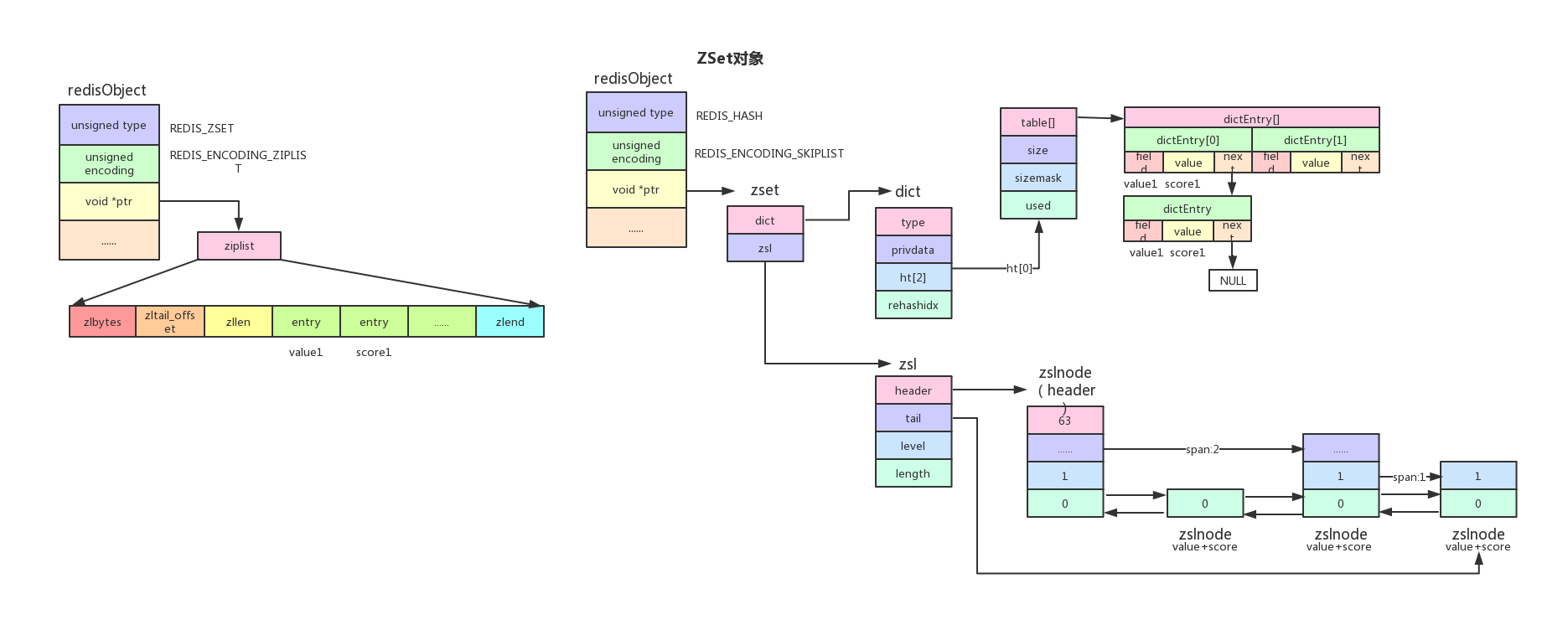
之所以采用hashtable+skiplist的形式存储zset,是因为这两种结构都各有好处。首先,zset是按照score排序的,skiplist的排序特性刚好满足这种需求;然后,hashtable保存了value和score的映射关系,可以直接通过value来获取score,时间复杂度为O(1)。假如没有使用hashtable,获取score就得在skiplist中逐层下沉地搜索,时间复杂度为O(lg n)。虽然同时使用hashtable和skiplist来保存zset,但是他们共用同一个value和score,因此不会造成空间浪费。
至于为啥zset使用skiplist实现排序功能,而不用红黑树呢?我总结出来主要有两点:
- skiplist实现比红黑树实现起来更简单,代码更容易维护;
- skiplist区间查找效率更高,跳表可以做到O(lg n) 的时间复杂度定位区间的起点,然后再顺序往后遍历就可以了。
关于skiplist,可以参考这篇文章:Redis内部数据结构详解(6)——skiplist












![[桜井宁宁]COS和泉纱雾超可爱写真福利集-一一网](https://www.proyy.com/skycj/data/images/2020-12-13/4d3cf227a85d7e79f5d6b4efb6bde3e8.jpg)
![[桜井宁宁] 爆乳奶牛少女cos写真-一一网](https://www.proyy.com/skycj/data/images/2020-12-13/d40483e126fcf567894e89c65eaca655.jpg)
